Every day we offer FREE licensed software you’d have to buy otherwise.

Giveaway of the day — Zentimo 1.4
Zentimo 1.4 was available as a giveaway on December 12, 2011!


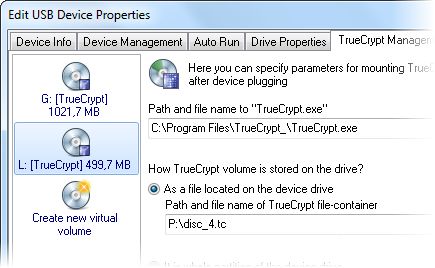
Zentimo offers a new way to manage your USB & eSATA devices. While it solves many removable drive related problems in Windows, it also gives more control over your external devices and just makes working with external drives fun & pleasure.
The program gives a highly customizable menu to manage external devices, displays what programs prevent stopping a device, speed ups your work with hotkeys, hides drives of empty card reader slots, allows to return a stopped devices back. Besides it lets you automaticaly run any programs on device connection\disconnection, speed test your drives, manage portable apps, has an enhanced drive letter management tool, integrates fully with TrueCrypt and much more.
System Requirements:
Windows XP/ 2003/ Vista/ 7 (x32/x64)
Publisher:
Crystal Rich Ltd.Homepage:
http://zentimo.com/File Size:
4.11 MB
Price:
$29.90
GIVEAWAY download basket
Comments on Zentimo 1.4
Please add a comment explaining the reason behind your vote.


#137 fubar,
Thank you so much for the information. It sounds like just what I need. I will download the trial and if I like it, buy it.
Thanks again for this and all your input on this site.
Save | Cancel
#112, fubar. Thanks for the suggestion--it seems backwards to me. I want to prevent a drive letter that I've already chosen from being assigned again to another device. I'm afraid that this software product needs better documentation than what's available on the web site.
So it's keeper now. Downloaded with no problems. Installed with no problems on XP Pro SP3 32 bit. Registered with no problems. Microsoft should have built this functionality into Windows.
Save | Cancel
Thanks guys. But I guess that's my point. I've been luck. I know not to pull anything out that's being written too before it's done and whats to stop someone from doing it with this program? I don't use the eject button. Not even on my ipod touch. If I'm copying something to a usb drive, I wait till it says COMPLETE. I guess I was trying to justyfy loading this program and spend "play time" trying it out but decided that I'll still skirt danger by doing things the way I've been doing for years. But thanks just the same for pointing out there's another way.
Save | Cancel
A nice idea. Some interesting options.
However, for some reason, it needed registering each new boot and bluntly refused to eject any drives at all - even with force release - something even windows generally managed. No use to me, Thanks
Save | Cancel
#160, Powder_Skier, Outpost complains about attempts to access critical registry areas, that's to alert you to potential threats (most aren't) and it's simply detecting access, whether it's actually a read or a modify. I don't like that they changed the default behavior for Pending File Rename operations to Block. While that's potentially dangerous, most of the time it's valid, as in the GOTD Setup. Prompting the user was causing the installs to fail the first time around while the user was answering the prompt. That was inconvenient because it required cancelling the installation and doing it again (worked the second time because the prompt had already been answered), but I liked it for other reasons. My Outpost Pro settings may be different than yours, mine is set to prompt but yours may be blocking other changes. Change your settings, or suspend it long enough to install (not normally recommended, but this is safe software).
Save | Cancel
Extremely happy with this tool. I had for a long time Vista not recognizing any external USB HDDs. It was absolutely frustrating not being able to use USB drives. I tried forums and all search acilites to get help, answers and solutions. I spent hours using techniques and all sorts of tricks that I picked up to get it working, but nothing worked.
Then comes this GAOTD offer and I could not believe it. I can again access all my external USB drives. Like a miracle, Zentimo 1.4 made my day!!!
Thanks heaps GAOTD, this was so far the best program ever.
HIGHLY RECOMMENDED for anyone with similar Vista problems.
Save | Cancel
Received key instantly to my yahoo inbox. Thank you GOTD and Crystal, just checked the features briefly, looks like a great program. It was always annoying me, having to unplug usb sticks when windows was telling me stick is still in use, but offered no solutions... looks like this program IS the solution. Yay!
Save | Cancel
Would not install. At 1:40 am it said the offer had expired even though GAOTD said their was still one hour twenty to go. I've never had that happen before...?
Save | Cancel
Outpost security said the program was trying to modify a critical registry area and blocked it. It didn't install and I'm not going to force the issue.
Anyone else have this problem?
Save | Cancel
Followed all steps, got registry key, but program would not open to allow it to be placed in appropriate Help_Registration file.
Save | Cancel
Got the license key right away in my Hotmail Spam
Copy and paste, Hit "OK" next comes up with a box with the following:
Registration is failed....Entered License information is invalid!
Save | Cancel
This is actually a really cool program. It tells a lot more information about the devices than I expected, and is very convenient. Yes, I realize Windows will tell you most if not all of this information if you go looking for it, but it's the fact that you have to go looking for it. This program organizes it all neatly in one place so you don't have to go far to find it.
I also really like the black velvet skin ;)
Thanks Crystal Rich for this neat little program.
Also for people having problems getting emails: Google emails work, GMX accounts work (mail.com), Yahoo works (had to logout then log back in), AOL works, Hotmail/Live/MSN works. I think that pretty much covers all major providers... (apologizing if I forgot any).
@122 The avast! sandbox option is a default to help protect you against programs it has not seen before/often. All it does is give you a chance to run the program in an environment where it cannot hurt your computer, but you can see the changes (all changes made while in sandbox will be erased). You can go into the settings and turn off the sandbox so it doesn't notify you every time you try to run a program. It never stops you, only suggests. If it bugs you, you can turn it off.
@126 For the norton/sonar thing - if an application has been recently updated or not downloaded much, it red flags everything. This can be ignored. It will try to automatically stop you from downloading or installing it - you can add an exception for it in your settings, or even (though I hate this option) turn off norton temporarily and then turn it back on after install.
Save | Cancel
Hi,
I did download and like the look and feel of the program.
One note: You automatically install various languages. It is a bit more elegant to allow only the install of the language we use. Granted it is simply a bit of space taken up, but I believe it is worth the time and effort not to have a couple of dozen language files cluttering the folder. I could probably delete the other languages myself, I think they are simply individual files that you access, but an install option is best.
Thanks !
Steven
Save | Cancel
re 20 above - this morning the USB midi keyboard still needed unplugging and plugging back in, so Zentimo hasn't solved that problem, but it's still a keeper.
Save | Cancel
Thanks to Crystal Rich Ltd and GOTD.
Easily installed and registered.
However, I have been using USB devices without any problems for years before this. It is not so difficult to observe the Windows OS rule to click on the green arrow (a.k.a. "Safely Remove Hardware") in the tray and wait until the all clear is given before pulling the USB connector out. If you do not want to wait for the green arrow all-clear, just make sure your PC is not in the process of writing anything to the USB device before you pull it out. Look for the LED light. Usually it pulses/flashes when write process is going on.
The usefulness of Zentimo is the identification of the drive with the memory card inserted. Without it, when using multi-card readers, we normally see many drives and you have to guess which is the correct drive letter holding the memory card.
I allow only a few software (such as ERUNT and AlfaClockClassic) to start with Windows. Will think about Zentimo in Windows Start-up if the memory overhead is not too high.
Then again it is simple to invoke Zentimo before one uses any USB connection; if you did not allow it to start-up with Windows boot. Actually you can invoke Zentimo AFTER you have inserted the USB device and it will function just as well.
When removing devices in Zentimo, beware. Clicking on the double green arrow removes ALL connected USB devices. Zentimo has a warning message to remind you. You may have hidden connected devices. I had two hidden devices that I want to keep running (my USB mouse and USB Bluetooth adapter). Click to reveal hidden devices. Go to the box of the USB device that you wish to disconnect and click on the grey arrow.
Thanks to Igor Tkachenko, who has introduced himself at the start and responded more than once to GOTD commentors. Much appreciated. Not many publishers in GOTD bother to do that.
Off hand, I can remember that Kryptel and AdMuncher also responded very well to GOTD commentors. I may have missed some others.
Save | Cancel
I've installed and re-installed and for a brief moment saw an icon in the sys tray. Then nothing. No icons on the desktop or quick launch, and nothing in the prog folder but the .exe. Zone alarms recognizes that it's there, but I can find no other evidence that it is up and doing anything. I plug in a usb drive, explorer sees it. Unplug the drive and explorer doesn't see it. In fact, I had a safely remove icon in the systray when the drive was not being written to, read from before installing this program.
I'm thinking virus scan drive and uninstall program. Windows XP SP3.
Save | Cancel
Never even knew this type of software existed to replace the native Windows program, but based upon the above reviews, I'll give it a try.
I shut down Norton Internet Security's Sonar function in order to install it, because it usually blocks the installation of GAOTD programs when it doesn't have sufficient info on the program in the cloud. Zemana triggered an Auto-start registry entry alert. Once those two things were addressed, I didn't have any problem installing it on Vista.
Thanks, GAOTD and Zentimo!
Save | Cancel
Comparison chart Zentimo to USB Safely Remove:
http://zentimo.com/zentimovsusbsr.htm
Save | Cancel
Installed and runs fine on Widows XP, SP3 and Windows XP Media Center SP3. I've been using this since the last GAOTD offer and it works flawlessly. Looking forward to the new features. Thanks to GAOTD and Zentimo
Save | Cancel
For those of you who read my previous posts, and for anyone having trouble registering, Igor was kind enough to resend license keys to those of us who wrote using the Zentimo website contact form (site is at the top of this page), and I suggest anyone having problems with registration go to their website and fill in the contact form to fix that.
To those of you getting the download flagged by your A/V software-IT IS A FALSE POSITIVE, you can disregard it, unless you prefer to walk away from this great piece of software rather than take our word for it. For Norton users - DO NOT let Norton "fix" the file or it will render it useless!
If you are having trouble installing it, or the install goes wrong, I can only suggest you download the file again after clearing your browser cache, and try again. The file "setup.exe" contains exactly 4,521,317 bytes according to 7-zip, and the CRC is 6E80BD64, if that helps. I have had problems in the past with files becoming incomplete or corrupted between clicking "Download" and unpacking with a Zip manager, so deleting the problem file and trying again is your best bet.
And finally - after reading over all the features listed on the Zentimo website, I have to say this does a LOT more than "just" giving us more control over USB devices - and its definitely a KEEPER IMHO.
THANK YOU Igor, CrystalRich, and GOTD for arranging this! This is one program I heartily recommend!
Save | Cancel
WOH!!
Fast, efficient and much more powerful than USB Safely Remove: just for once the current GAOTD User rating perfecly reflects the real value of the software!!
TWO huge THUMBS UP from me and ANY better FREEWARE ALTERNATIVES today, apart from (maybe) an amazing and pretty unknown FREE tool called "USB REDIRECTOR CLIENT", enabling users to gain access remote USB devices via local network or internet.
Yes, you heard me right dudes: with this awesome APP you can work with an USB FLASH DRIVE, despite not being plugged into your computer.
In fact, what you have to do is only to install this software both on the system where your USB FLASH DRIVE is plugged in (for instance at home) and on the PC where you are going to use USB device remotely (for instance at your work place).
COOL, isn't it?
So it's definitely a very useful USB management tool, especially for users with a corporate or a home LAN network or for those using a PC with damaged or missing USB ports!!!
Download:
http://www.softpedia.com/get/System/System-Miscellaneous/USB-Redirector-Lite.shtml
Screenshots:
http://www.softpedia.com/progScreenshots/USB-Redirector-Lite-Screenshot-136989.html
Just give it a try to see how handy it may be for you!!
Enjoy & Prosper!!
Save | Cancel
After I installed and registered the program successfully on WinXP SP3, all of my networked computers disappeared from "My Network Places". I can see this computer from all of the other networked computers though. Doesn't look like anyone else has had or noticed this problem yet. I did create a restore point before I installed the program. Looks like I'll have to restore if I can't figure this out.
Save | Cancel
#119 Mike,
Re: Norton Sonar. Just bring up Norton and toggle Sonar off (default is for 15 minutes, which will give you enough time to run Setup.exe). Sonar should have removed Setup.exe, but allows a restore if you clicked on the popup. Otherwise, just re-download.
Save | Cancel
Just a confirmation that there's still an email issue about 4.5 hours after the last moderated/visible comment (#127). I'm sure they must be trying to rectify things, even if the support address hasn't responded to emails yet.
For anybody not familiar with past procedures here: they might lengthen the email period to compensate for their delayed responses, but you probably still have to install the software itself while the giveaway's active. (However, even that's been extended as part of the response to past registration issues, so stay tuned.)
Hmm, wouldn't it be cool if something to that effect was posted on all the giveaway pages so newer visitors wouldn't get nervous about glitches as long as they're reported? ;)
Save | Cancel
I am also a paying customer of this program. I am so satisfied with it that I will be renewing my PAID subscription later this month, rather than taking advantage of this chance to get a year for free. I appreciate this program that much. Get it today and try it out for free, is my recommendation.
Save | Cancel
I've been using this for a while. It's an invaluable tool, if like me, you live with some less than tech savvy people, who were always stopping the whole internal card reader or the wrong usb device (scanner, usb wifi, etc) when removing their memory card or flash drive.
Save | Cancel
I would like to know what is the difference between this Zentimo Pro offered here as a GOTD today, version 1.4, size 4.1, and the same software offered at the Zentimo site, version 1.4, size 3.2 MB, which you can download after you have sent them a request for the free license, why the difference in file size?
Save | Cancel
Tried the license email with 5 different addresses, sent the email for feedback and got the reply but nothing else. Finally after 18 hours I tried again and got the licensing email on the first email address I tried. When I tried installing it orginally Avast asked me if I wanted to use the Sandbox to install it, but I opted no, its been working fine....so far. Need to do something about the license glitch, usually there's no trouble from the website in question about registering.
Save | Cancel
Igor said "Zentimo contains almost all features of USB Safely Remove." Almost? What's missing from USB Safely Remove? One comment above said there's no longer a help file, anything else missing?
Save | Cancel
Great program - easy install and does just what it supposed to do. This is a keeper. Thanks Zentimo and GOTD team!
Save | Cancel
I redownloaded the zip file and didn't get an error this time. All is good.
Save | Cancel
RE # 19
"19.Gee Zentimo is promoted so often I’d hate to be a PAiD License Holder, because I’d feel ripped off, especially as they NO LONGER OFFER a GENUiNE LIFETIME LICENSE and haven’t done so since late August 2009 when they chose to become microsoft style tycoons."
I purchased a lifetime license inc all upgrades in Aug last year so I'm not sure what your referring to.
Zentimo has had issues though the best thing is that the developers are active and are very responsive to user comments and suggestions so as Igor says it can be continually improved. That's why i paid for the Zentimo lifetime license. Recommended.
Save | Cancel
#116, joe, I use a former Giveaway, Blue Project SysTracer Pro. It has many, many features. In addition to tabs and the buttons all around the UI, try clicking, double-clicking, and right-clicking things. It's on sale for the next couple of months, and a home license is available. The trial conceals a lot of information, but I recommend trying it before you buy to get an idea of the sheer quantity of information that's generated by Windows during normal operation and installations, it could take a while for you to learn if you're not familiar with the internals of Windows. Tracing shows the end result of installation or running. If you need to delve into installation as it happens, security software can help, and there are always Sysinternals tools like Process Explorer and the extremely detailed Process Monitor. You'll note that a great deal of vote manipulation has been going on for the last couple of months, but GOTD hasn't done anything to rectify the situation. An inconvenient solution would be preferable to the current meaningless, manipulated values.
Save | Cancel
Running Win XP SP3, fully updated. Zentimo 1.4 downloaded quickly. In order to install under Norton SONAR, I had to manually allow the .exe file. Zentimo installed perfectly. I received license key email instantly and registered with no problem. Looking forward to using the program. Thanks GOTD and Zentimo!
Save | Cancel
Never had the slightest problem disconnecting/reconnecting external pen drives or USB hard drives with Win 7. Just wait until the led light stops flashing on the USB device. Doesn't take more than a few seconds at most, so why should I need software to manage a very simple process! All of my USB devices run plug and play, managed entirely by windows. Never even need click the remove icons safely icon. Not had any data corruption on any USB drive, and not had any problems with USB devices being removed and replaced even many times in one session.
Today's GOTD may be useful with XP to prevent unnecessary reboots but this simply doesn't happen with Win 7 Ultimate x32. USB stable as a rock!
Save | Cancel
How many years shall i wait to get the license? I tried three different email providers none received any mail from Zentimo. Every time i tried the page said registration ok, mail is on the way.
Save | Cancel
To those of you who have a problem getting the License; did you read the "Read Me" file? It says to go to
http://zentimo.com/giveawayd11.htm
to signup for the license.
I had no problem getting the code.
Save | Cancel
7x64 No problems - I was expecting some tricky registration issues from the previous comments, but discovered it was straight forward, step-by-step instructions r provided 4 u IF u decide 2 read them, or if u thought u read, read more thoroughly.
Save | Cancel
Follow up to my last post (127) - I have now received the license key - Many thanks:) - There seems to be an initial delay in getting the key, but it eventually arrived, so anyone waiting with luck will get one soon - Thanks again for an excellent Giveaway...
Save | Cancel
Nay! Once uninstalled this soft I MUST to reinstall card reader driver, because it has been blocked by this soft. Thukb down
Save | Cancel
A question for Igor.
I had installed the Previous version 1.0 on both a desktop machine (XP-Pro) and a netbook (W7). After I had imported all kinds of custom icons on my desktop machine I didn't want to do that all over again on my netbook so I found the location where these icons were stored by Zentimo and copied them to the equivalent directory on the netbook.
Unfortunately Zentimo 1.0 didn't automatically show these icons in its list of available icons. I don't want to use the function where things are written to the storage device I just want to export/import these icons I used between Zentimo installations.
How can I do this? I noticed a "Save to file" And "Load from file" Options button in the bottom left corner that wasn't in version 1.0. Will this export/import all the settings AND the icons?
Also what is the size of the icons Zentimo shows in the list so I'll know which icon size I can best use when creating them.
And why is there no Help function? The Help button is greyed out on the settings window.
And thanks BTW for making this available to us for free today. :)
A suggestion. You should 'collect' a library of icons and make it available as a download. It's very convenient to recognise at a glance the device you want to remove in the list when the icon is just a miniature picture of the device. I have found icons or created them from photos (Google image search) of all my devices from a Sandisk Cruzer Blade USB stick to a Kodak Zx3 Pocket Video Camera and all of my external hard disks (Western Digital, Seagate) and even my Kingston Card Reader and my Pocket PC's and my Android Tablet etc.
You could ask people to help collecting/creating them and have them send their icons to you so you can make them available on your web site. You could even add a link in Zentimo to this collection of on-line icons so you could search for the icon you need directly from Zentimo in this on-line database.
Great idea right?
Save | Cancel
No license key sent to my email, and no reply from support yet or no reply from feedback - My spam filters are not blocking either support@zentimo.com or support@crystalrich.com
This seems to be affecting some others here also...
Save | Cancel
Not having luck installing on my Win XP SP3. Norton Antivirus v16 gives me a risk warning & removal via SONAR and won't install (using 7-Zip to run setup.exe). Bounced over to pkzip and MalwareBytes gives me a malicious program error. No dice for me.
Save | Cancel
I can't unzip the zip file. I get error: Invalid compressed data to inflate. How do I fix this?
Save | Cancel
I always virus scan any downloaded files before installing. I also received the Norton Antivirus v16 SONAR warning about setup.exe containing a risk and the risk being removed. The program did not install. Windows XP SP3. Any thoughts?
Save | Cancel
It uses about 3x as much RAM (about 30Mb vs 10Mb). Just to control USB devices better? So I guess it's got to be better than USB Safely Remove..
That puts it between my email client and file manager, and explorer and Kaspersky, at 7th from the top.
Save | Cancel
Dear Swaminathan,Commenter #83 - Yes ,my Avast recommended opening in sandbox-But Avast is not always right-false positive. Runs great,no problems,no problems with install,Win7 Home Premium,got emails with subscription request/Serial instantly,[ Gmail ] ,Activated,[no upgrades to future versions],, KEEPER !!!!!
Save | Cancel
Very much clearer GUI than last I looked at this and couldn't stand it..
An invaluable tool.
I wonder if it will manage USB drives with several partitions any better than USB Safely Remove, or will Windows still win?
but what does (in red)
Note! You have to use %Driveletter% template in the command line to pass a drive letter to the file manager
mean?
(Under Options, behaviour,, Browse devices with (and check) 'An alternative file manager, and enter a path to it).
Clearly needs a local help option.. with examples- and it's greyed. out.
This level of techno jargon really shouldn't be needed to achieve something fairly simple, I suggest.
Save | Cancel
Thanks GOTD and Crystal Rich. I will definitely give this a try since I have been using USB Safely Remove since its giveaway here last time.
Save | Cancel
Has anyone else had Norton Internet Seurity SONAR abort the setup?
Save | Cancel