Every day we offer FREE licensed software you’d have to buy otherwise.

Giveaway of the day — Text-R Professional 1.100
Text-R Professional 1.100 was available as a giveaway on September 11, 2020!

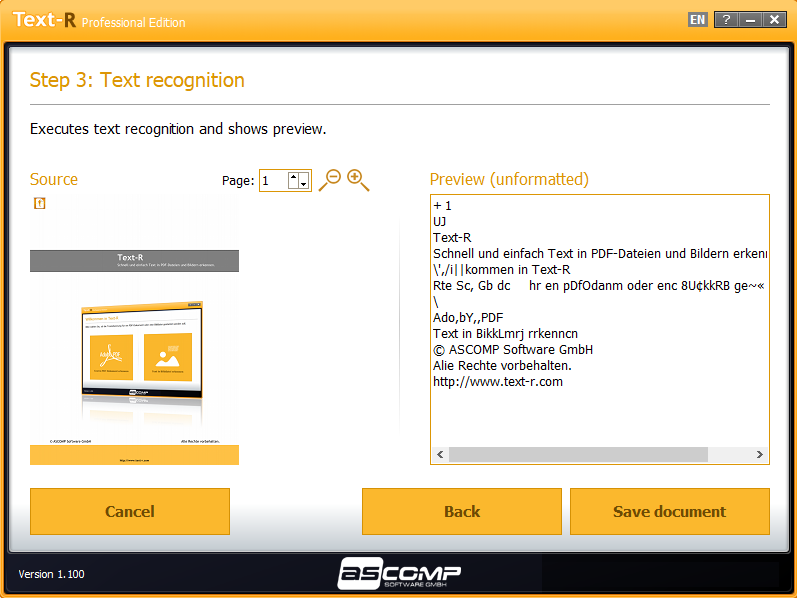
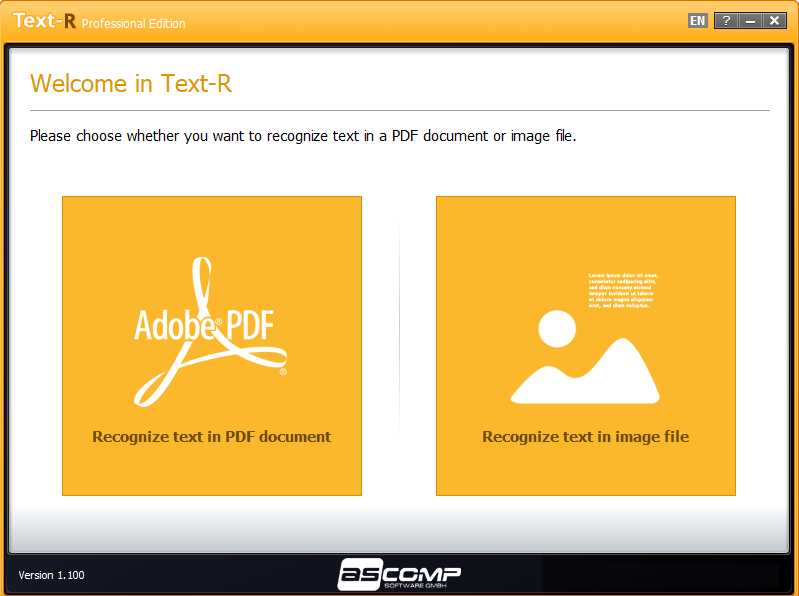

The problem: PDF files and images from a scanned paper document contain text that cannot be copied or edited. However, manual typing is not possible due to the size of the document and the high time involved.
The solution: Text-R! The software also recognizes text in PDF files and images that can be operated immediately for the layman. The text can be saved in a new editable PDF or RTF document (Word). Formatting stays close to the original, so in most cases, no post-processing is required.
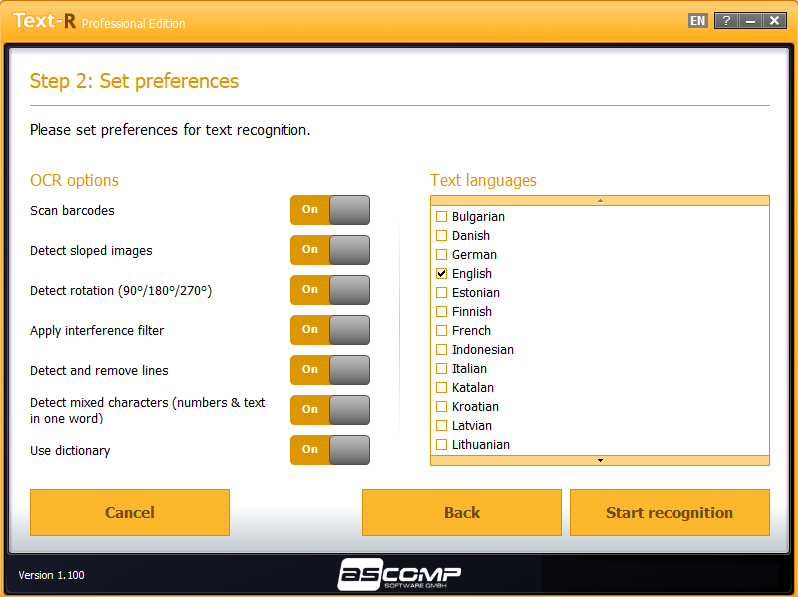
The built-in dictionaries and professional OCR filters ensure high accuracy in text recognition. In this way, skewed texts and rotated documents can also be detected.
Please note: The giveaway only contains the text file with a registration link, the custom installation file will be available upon license registration.
System Requirements:
Windows XP/ Vista/ 7/ 8/ 8.1/ 10 (x32/x64)
Publisher:
ASCOMP Software GmbHHomepage:
http://www.ascomp.de/en/products/show/product/textr/tab/details/?design=redesign2019File Size:
0.59 MB
Licence details:
annual
Price:
$33.90
GIVEAWAY download basket
Comments on Text-R Professional 1.100
Please add a comment explaining the reason behind your vote.

very disappointed, went online, filled out all the details and waited, no email with link, still nothing next morning, hope I don't get marketing stuff from them now
Save | Cancel
Program works well and is fast, easy to use. I tried about 10 PDF files and 1 image file. Some PDFs had text in images, others had selectable text. I would assume for selectable text, the program does no OCR but simply grabs the text, it's pretty much exact. When it needed its OCR engine, some odd text resulted where it tried to interpret symbols & logos as text, but othewise I didn't see any translation errors in most files. The image was of a store order with item pictures, prices, descriptions in several columns, not lined up in rows. All the text and numbers were captured accurately and even grouped as expected (by item, not across & down). Very nice!
One PDF file gave it a problem. No text was found even though it contained text and images with text. And yes, I used the page function to look at pages after the first page. One unreadable file out of about 10, that means the odds are pretty good that I can extract text when needed. With a spell checker in another program, most OCR errors should be fairly obvious and easily fixed -- in my experience they were rare.
I did not try saving the file out, just looked at the preview text. So I don't know how it would have saved out the store order, but I rarely worry about that. In almost every case, I'm trying to grab the text or part of it, and formatting is not important to me.
Thank you GOTD and ASCOMP Software!
Save | Cancel
The download was a bit tedious but pretty easy. However, as best I can tell the free download is only a six month license. I am not sure the download and learning curve are worth it for a six month license (but if you really it loved the $15 upgrade for a couple of years might be worthwhile).
Oddly enough, it pulled the text from normal PDF files pretty well and did OCR of jpeg files pretty well, but if the jpeg was embedded in PDF file is did very poor OCR. Strange.
Save | Cancel
I did the registration and I get an error message that the License Number has been used already or is in valid and that number is filled in from the link
Save | Cancel
Jeff Homley, just tried it, passes OK. Are you using a proxy? Maybe try a different browser.
Save | Cancel
Does it scan Cyrillic, Greek, Hebrew, or Arabic? I use Russian and Greek frequently. I also use French and Spanish often and occasionally Italian.
Save | Cancel
Fr Michael, the program allows for multiple languages to be scanned and used. When you select a file to have 'OCR'd" you select the language of the file and it does the rest. Have not tried it myself as English is the default selection. Give it a try and let us know, please.
Save | Cancel
First of all, if it matters to anybody, these are the same people that put out Synchredible, the best file Synchronizer on the market.
That being said....
I have a special folder in which I keep some really awful PDF files to test out the grandiose claims of OCR converter software. Text-R bit the dust just like everyone else's program. The converted page was just full of garbage.
Now.....if ASCOMP is interested, I would gladly send my test PDF to them to play with. I just need an address where to send it.
Save | Cancel
Agreed, [ CJ Cotter ], this is more for convenience to grab brief text rather than re-write, especially to get the content of error messages and such for quoting and submission, screen text presentations that do not respond to highlighting.
I also have unOCRable scans, and I have to export them, one page at a time, to Photoshop, clean them up with a series of background selections to eliminate the vignetted gray backgrounds, and some publishers use screening to make themselves unscannable ( knitting patterns ), they are fun, it take hours to beat them.
OCR from a picture of text has many phases including squaring, straightening, text-to-background contrast-enhancing, defogging, sharpening, anti-aliasing.
And then the fun begins for recognizing characters themselves, then trying to figure out the presumed meaning of each individual character in the context of words and sentences ... in whatever language, dialect, and colloquialisms of your choosing.
Then figuring out the meaning of page elements like footers, headers, page numbers, pull-outs, images and captions, notes in margins, and so on.
No one, absolutely no one appears to address all of this.
But full-fledged scanner OCR programs do have iterative "please correct me" modes where basically, we need to read through the entire project, word for word, character for character, beginning to end, to correct errors, and the programs promise to learn, but they never learn.
Anyone can find bad PDFs on the web, no need to presume ASCOMP does not know they exist.
So, again, this software is more for convenience to grab brief text rather than re-write, especially to get the content of error messages and such for quoting and submission, screen text presentations that do not respond to highlighting, and that's what I use it for, occasionally.
.
Save | Cancel
Peter Blaise, For very brief text in an image for which you need the text, perhaps it is faster to use a dictation app, or the Dictation or Transcribe feature of Word (the free version on the web). They are at least as good as some of the OCR.
Save | Cancel
Very impressed, downloaded and installed with no problems. Tested using a few pdf's, output far better than I expected. Have no problem recommending.
Save | Cancel
Has anyone compared this to the free Tesseract engine?
Save | Cancel
OldGuy, did you mean as opposed to its paid version?
Save | Cancel
Installed with no problems. It has a small fixed size window, difficult to read, especially white text on yellow background. But the real problem is that the text must be sharp and clear in the original pdf. I tried some originals scanned on a Canon scanner and this is one line that was converted with my quote marks added here: "Gtatommt T)m0· Fchnmrv 1 ?(])1) thrcmah Fohrnaru )Q :mm J ' GP J ' " The original was printed text, and I can easily read it, but the program could not. Here is the original that I am manually typing in for this comment: "Statement Date: February 1, 2020 through February 29, 2020" Considerable manual correction would be needed. Other pages were better converted, but all had problems so every letter/character needs to be verified, and this is typical of any OCR software I already use, but most allow verification and correction inside the program.
Save | Cancel
Leo, so basically like every other free OCR. Wish these could identify the characters easily.
If anybody knows a good OCR especially one with central european char set pls tell.
Save | Cancel
I downloaded this program when it was up before
It does work for about 75% it does actually convert pdf/text pictures to TEXT
I suggest you convert to PLAIN TEXT, converting to DOC file only about 65% accurate.
My rating 7.5 out of 10
Save | Cancel
Q1: Is the OCR done on the local machine or is it client-server, or some hybrid?
Q2: Who's OCR engine do you use? (Aabby, Google, Other)
Q3: What are the performance stats or comparison on the OCR
Save | Cancel
Spam Sorenson,
The same version (1.100) of this was offered 6 months ago on March 12 -- your questions are answered there among the comments (see #27), although I did not notice any "performance stats" mentioned:
https://www.giveawayoftheday.com/text-r-professional-1-100/
Also, since I installed it then (and won't bother to replace it today), apparently some of my own observations have not yet been addressed (comment #30).
Save | Cancel